Cleansing Data With Tamr
Tamr combines machine learning software and world-class data science expertise to provide insights that help some of the world’s largest brands drive savings, optimize spend, and reduce risk – using all of their relevant data. In many large companies, data becomes siloed, making it very difficult to understand a holistic picture of the organization. By removing these silos and creating a unified and enriched view of all customer data, companies including Toyota Motor Europe, GE and Thomson Reuters are:
• Providing better service by unifying customer data from multiple channels
• Identifying key opinion leaders within the organization
• Reducing customer churn by improving the data quality of life-cycle analytics
The client for this project had many different customers listed across many different data sets. They wanted one unified list of customers. Tamr's machine learning cleans up these data sets, and the Scrutiny App was intended to allow the client to check Tamr's work.
Team Structure + My Role
Scrutiny App Project Team: 3 Field Engineers, 1 Customer, 2 Developers, 1 Project Manager, and myself as a Product Designer
As a Product Designer, I synthesized varying perspectives and needs on this project.
• User Research
• UI/UX Design
• Interaction Design
Goals
Have a way to easily see if the machine learning algorithm is sorting customer data well. This involves looking at rows of data and seeing how the algorithm grouped (otherwise known as "clustered”) data, and where it did not cluster data. Ultimately, the client should be able to inspect their data around specific customers more clearly on the Tamr dashboard.
Process

Phase 1 Observation
We realized that a lot of the communication around model performance happened during phone and video conference calls, and would be followed up with an email exchange. Therefore, we decided to observe Field Engineer meetings with client to identify pain points in the communication between the Field Engineers and the Client.
Additionally, we held roughly 4 feedback sessions on designs between Field Engineers and Design/Engineering.
Observation Insights
Discussing how well the machine learning grouped like-items and separated disparate items was difficult for a variety of reasons:
• Communicating by phone and video can be challenging due to dropped calls or poor internet connection during screen sharing.
• The client wants to see the rows of data that were processed by Tamr’s machine learning. They want to manually review results.
• The client has a rough idea about what the data should appear to be like, but has trouble articulating it.
• The client wants to see data in a way that shows them a clustered customer (Note: a clustered customer is one where all rows of data, from a variety of sources, relating to a specific customer are grouped together).
Actionable Items
• Lightweight metrics around overall data performance
• Search and Browse clusters + records of data
Phase 2 Ideate
As a project team we used wireframing and white-boarding sessions as ways to collaborate on ideas and communicate with each other. Below are some clips from my notebooks.

Phase 3 Prototype + Visual Design

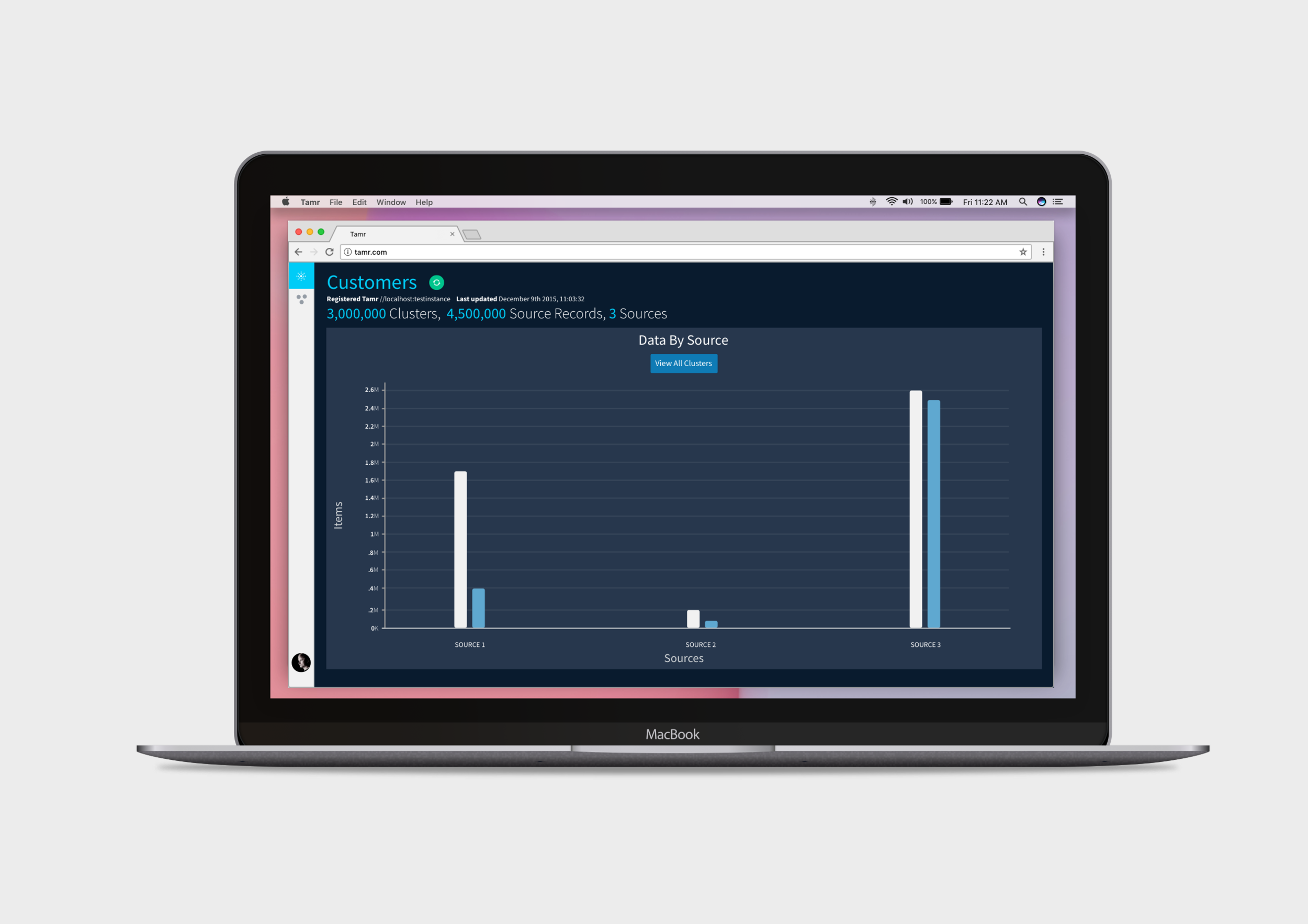
Dashboards
We began with a one page dashboard to see how we could communicate overall machine learning performance. Below are some dashboard explorations we tested.
Much of Tamr’s platform is about showing “cleaned-up” data. In this dashboard we wanted to communicate to the user, at a high-level, if their data was in good shape, or if they needed to guide the machine learning algorithm more. We explored a variety of visuals to show if a dataset was in good or in bad health.
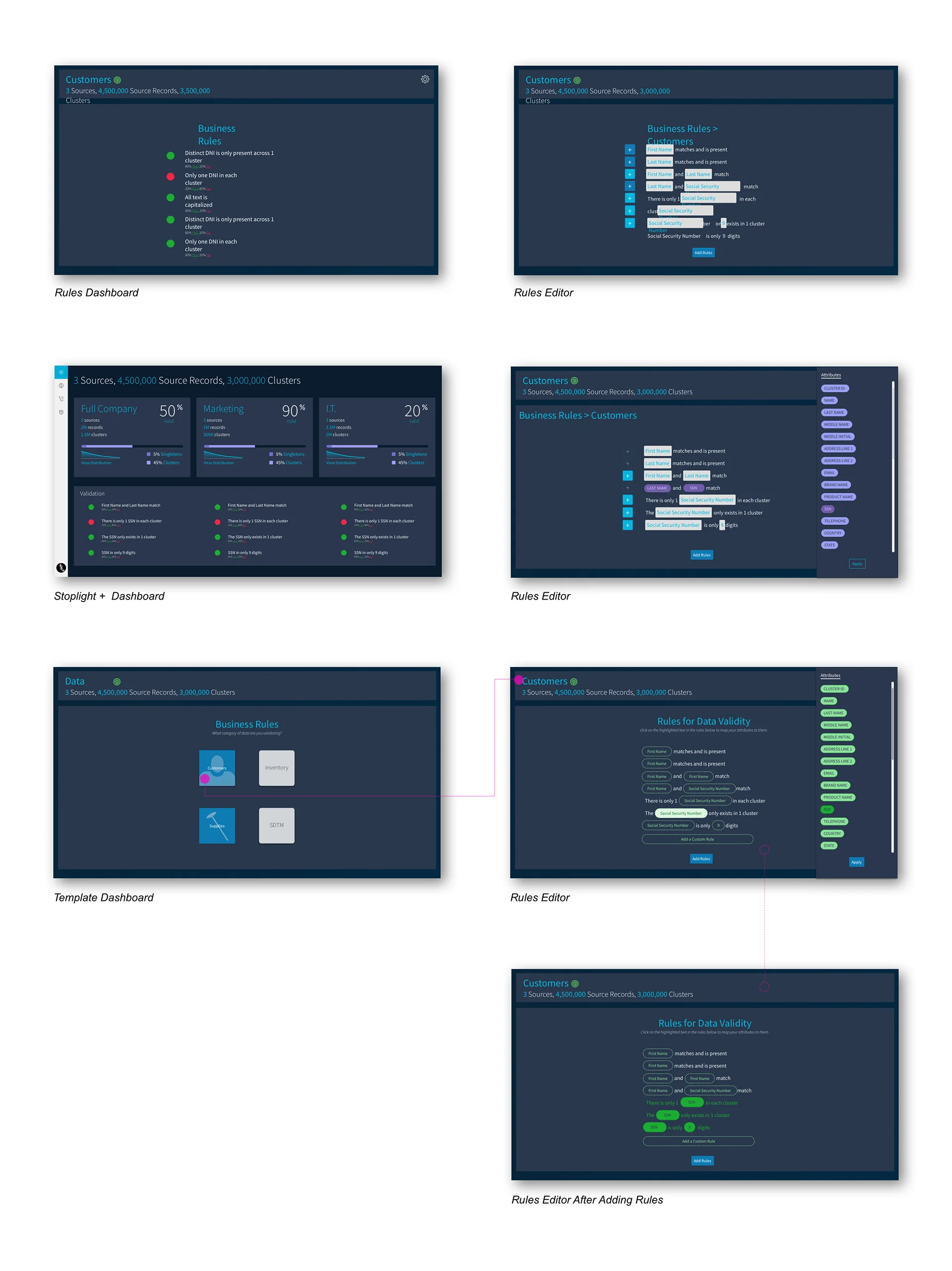
Rules Generator
Through conversations with the Field Engineers, we tried to extract information around what would be high-level indicators that the machine learning model was performing well.
We spoke with Field Engineers to ask them for basic understandings around how someone could at a glance know that customer information was accurately grouped. An instance is if First Name, Last Name, and Social Security Number all match, there is a very high likelihood that all rows of data belong to the same person. However, Tamr is not a rules-based system and this would not be technically feasible.

Search and Filter
Through further thinking, we realized these rules were simply "saved filters". We shifted from focusing on rules in a dashboard that act as an alert system (i.e. Not all Social Security Numbers match in this group of rows that have been clustered) and focused on designing and building highly functional search capabilities on the data.
Here we explored possible forms of search formats, from column and row filtering, to a global search.
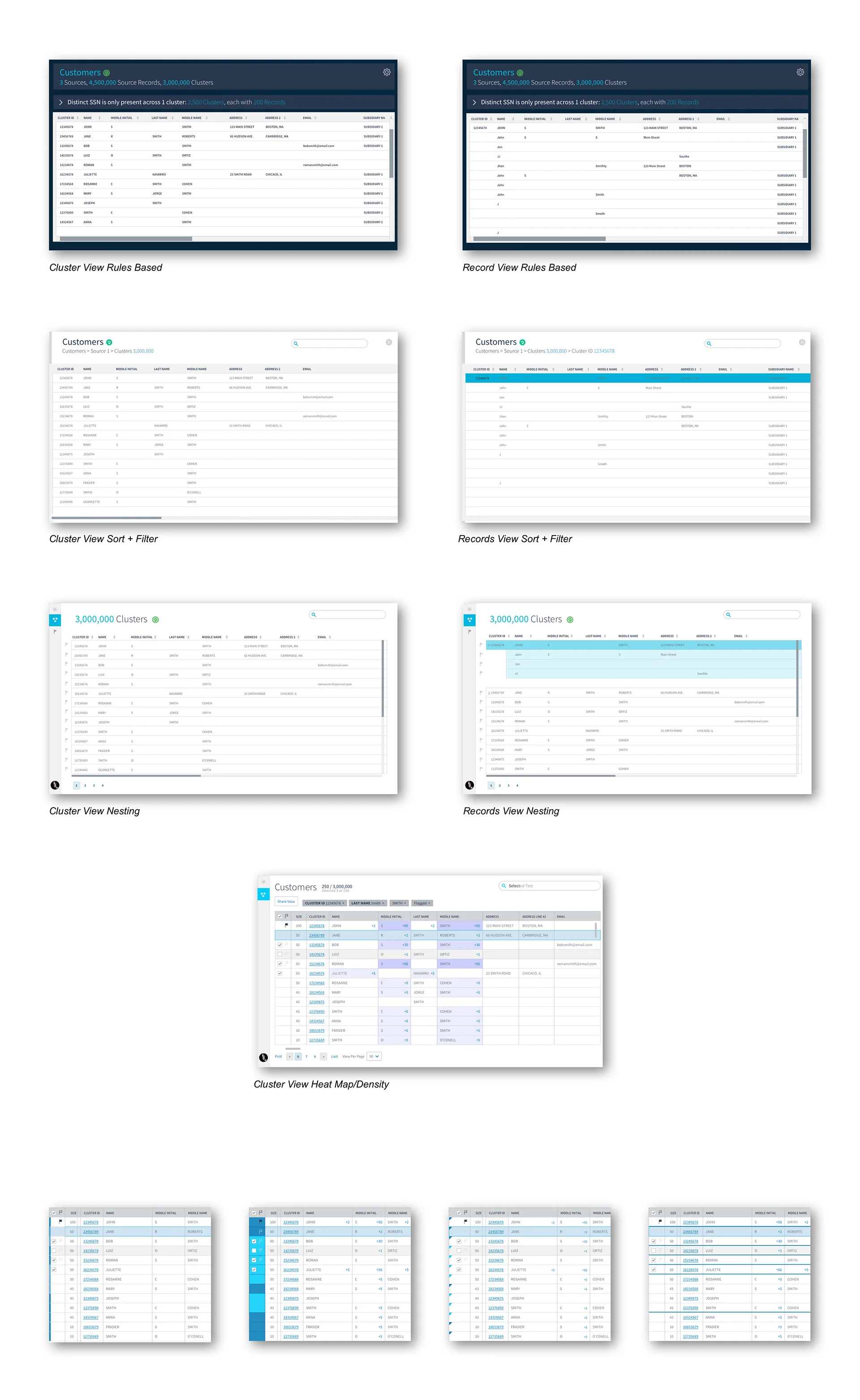
Clusters and Records
All of these capabilities to highlight information about the clusters (groups of rows e.g. a single customer) and records (rows) within the system. We needed to spend some time around how we wanted to display a cluster vs. a record within this data validation app.
We tried separating them into different pages, having them nested, and creating a heat map. Additionally we tried various visual cues to indicate a record vs. a cluster.
Phase 4 Implement
Build the MVP.
In the end we landed on an app that consisted of 3 main screens: a dashboard, a page to view and interact with clusters, a page to view and interact with records. The landing page acts as an action-driven dashboard. This dashboard provides some high-level metrics around the data sources being used to identify the customers. From there, the user can go into exploring the clusters (customers) and do a visual check to see if the data fits their mental model. The user can click into any cluster by clicking on the cluster ID number and it will take them to the records that make-up that cluster. In the cluster page, there is a numerical indicator of how many additional values are in each cell. This is useful to understand data variety in any given cluster.
Lastly, as there were some technical/time limitations for implementation, we wanted to allow users to get their questions answered in real-time, whenever necessary. To achieve this, we created a share button that lets users copy and paste a url—allowing the Field Engineers and customer to see the same screen at the same time while on a phone call.


Next Steps
This project happened while the core Tamr platform was being re-configured and therefore this application sat outside of the core product. The next steps would be to speak with other clients and see what their data validation needs would be, and re-integrate this platform to the core product. Additionally, it should undergo more rigorous user testing with customers for more in-depth validation of features.